I’m thrilled to share that DeepSeek has just launched a brand‑new open model for document recognition—DeepSeek-OCR. Unlike traditional OCR systems that merely pull raw text from pages, this one instantly reconstructs the full structure of a document: headings, lists, tables, figure captions and more. The output comes in Markdown format, which is perfect for indexing and feeding into downstream neural networks. DeepSeek-OCR is released under the MIT license and can be found on Hugging Face.
The standout feature of this release is what we call “contextual optical compression.” The model doesn’t replay every single pixel; it distills only the essential text and its semantic structure. This reduces data volume by an average factor of ten to twenty, cutting downstream processing costs because fewer tokens mean cheaper and faster language‑model inference.
DeepSeek-OCR employs so‑called visual tokens—essentially “glimpses” of image patches. Even with a modest token budget (64–100 tokens), recognition accuracy stays between 97 % and 99 %. When a page is too complex, the model switches to its Gundam mode: it automatically splits the document into separate fragments and analyzes difficult regions independently, all while maintaining overall speed. It also supports mapping recognized elements back to their coordinates on the page, which lets you pinpoint tables, figure captions or diagrams with precision.
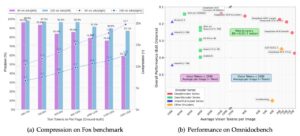
On benchmark datasets like Fox and OmniDocBench, the system delivers impressive results. On Fox, accuracy remains virtually unchanged even at minimal visual‑token counts, achieving up to twenty‑fold compression. On OmniDocBench, DeepSeek-OCR maintains a low error rate while using far fewer tokens than heavyweight multimodal models such as Qwen or GOT‑OCR 2.0. In short, it offers comparable quality with significantly less computational overhead.
Leave a Reply